Why failure is important in prompt engineering?
Sep 10, 2023

I previously talked about what is prompt engineering and how it requires a skill that is common amongst engineering disciples, the ability to re-frame and decompose a problem into smaller pieces.
Today I want to go deeper into another aspect that is overlooked when it comes to prompt engineering. Unlike other roles in tech, where we are primarily considering the happy path and perhaps a few edge cases, failure is the thing that brings the most significant insights and rewards to a prompt engineer.
Prompt engineering is similar to structural engineering. It requires us to put prompts (our materials) to their extreme limits. Much like testing the breaking point of materials in structural engineering - rigorous testing of our prompts for various inputs helps us understand the boundaries of our answers to avoid over-promising in practical applications. Once we understand the boundaries we can then adjust, calibrate and if needed fine-tune our models to our specific use cases and develop a way where good, consistent, outputs can be obtained.
This is an important concept to understand because collecting and analyzing those failures will bring us closer to refining our prompts in a way they can deliver on the task. For small things, making a simple prompt can work, but when you actually need to use LLM into real life products, you realize that the input and outputs have a high degree of variation. This is likely going to hold back deployments of LLMs in high stakes and highly regulated industries.
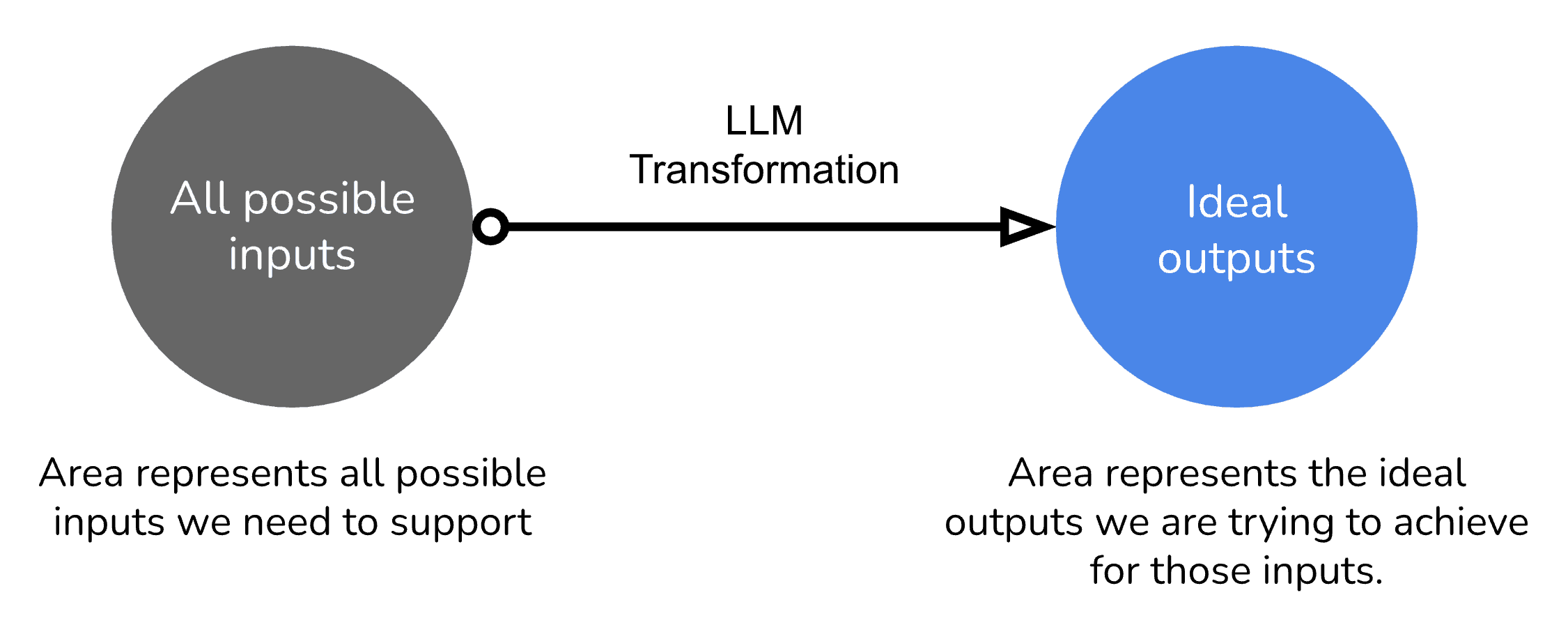
Many times what we are trying to achieve with software is to do a series of transformations on a specific set of inputs to get a specific set of outputs. This is especially true in Prompt engineering. While building NetworkGPT we integrated with 15+ private and public databases, resulting in an inherently large variety of inputs. Here is the framework I used to understand the boundaries of my prompts.
Consider the ideal inputs & outputs
Consider the ideal set of inputs you would like to support and the ideal outputs you would like to achieve.
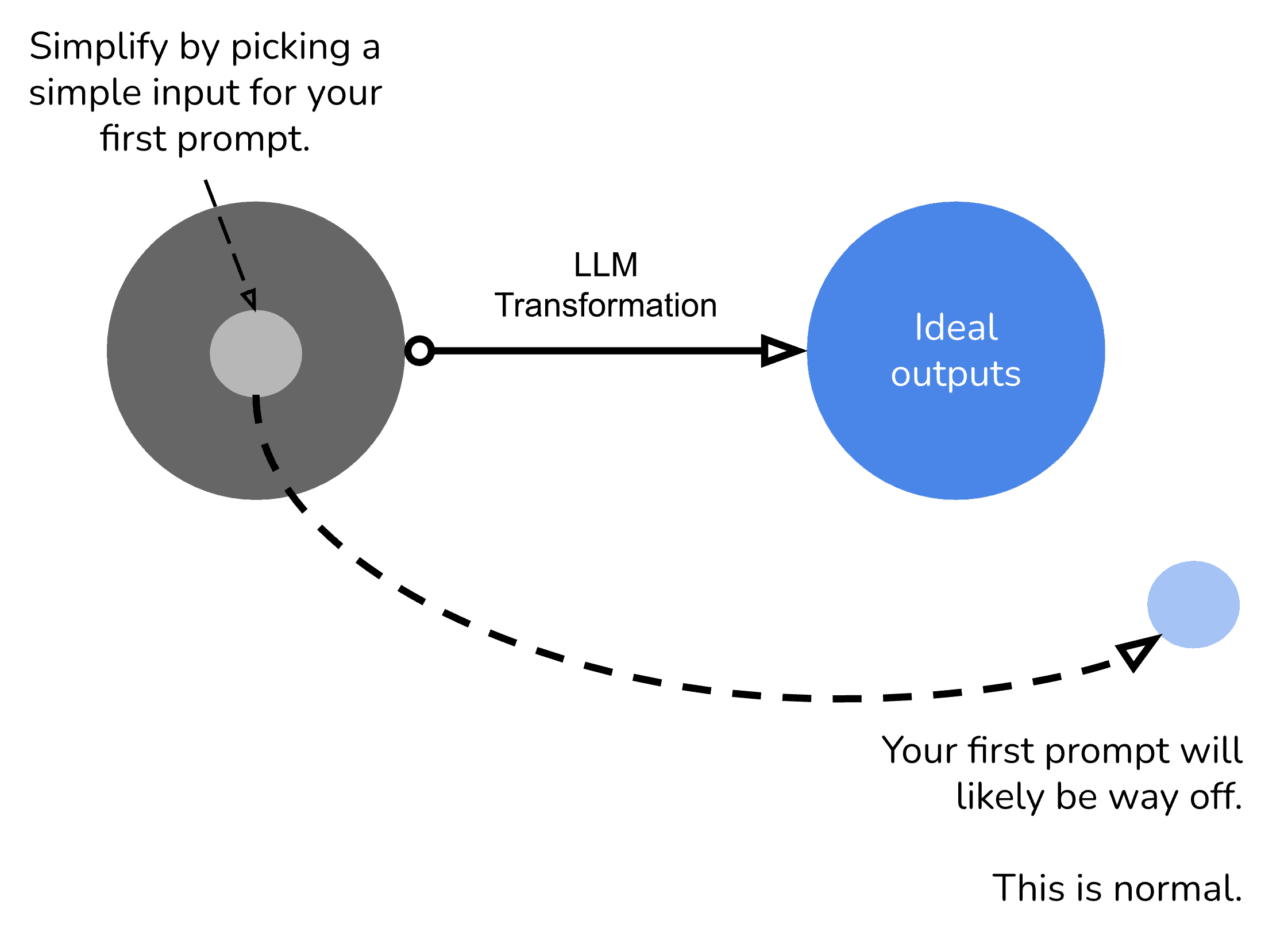
Create the first prompt
Create a first prompt by taking one ideal input, reframing and decomposing the problem. This post dives into this further.
Through reframing, move your prompt closer to your ideal output
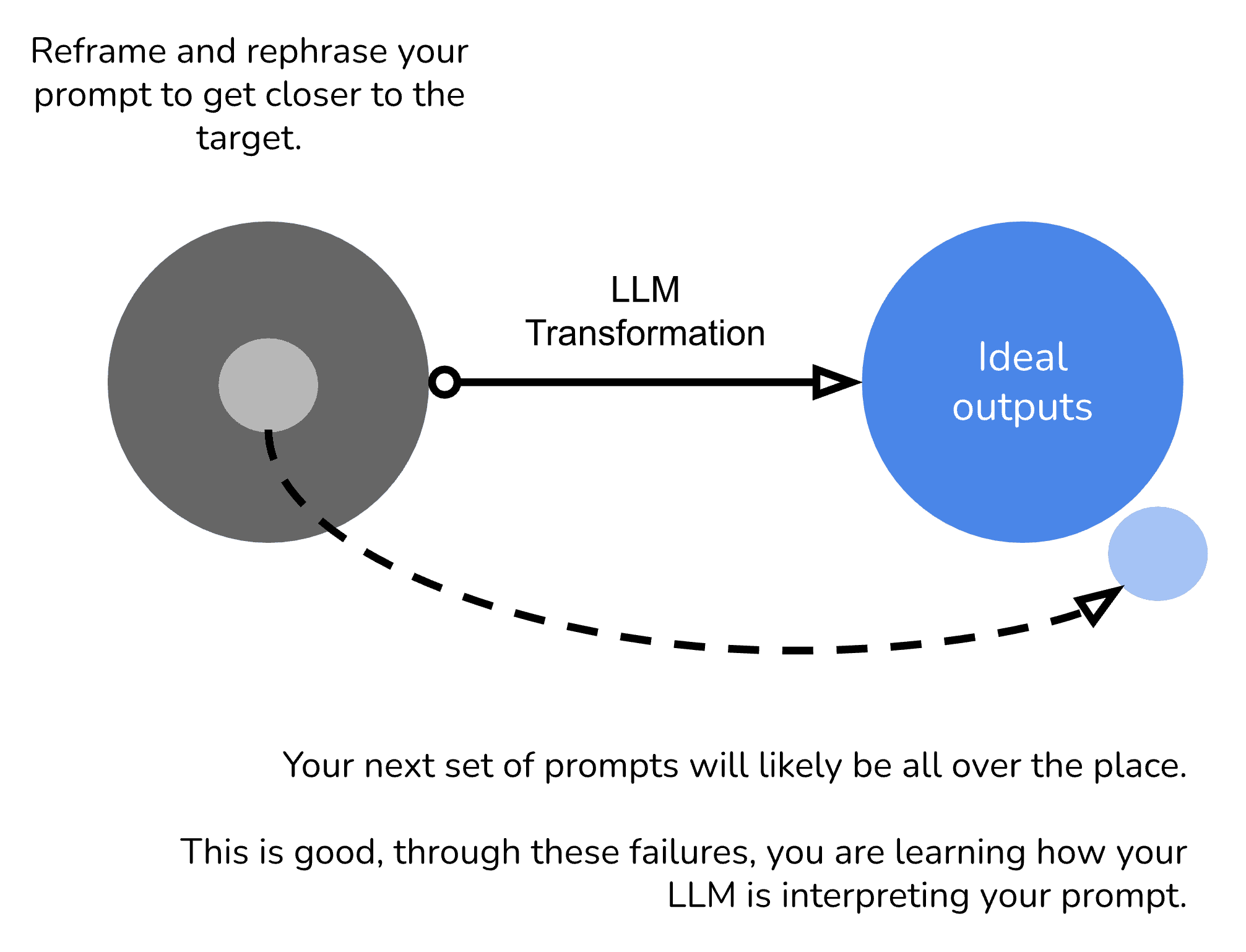
You’ll then find a prompt that is working well. It likely won’t have the ideal output, however will be within the range of what you are expecting. Don’t worry if it’s not perfect.
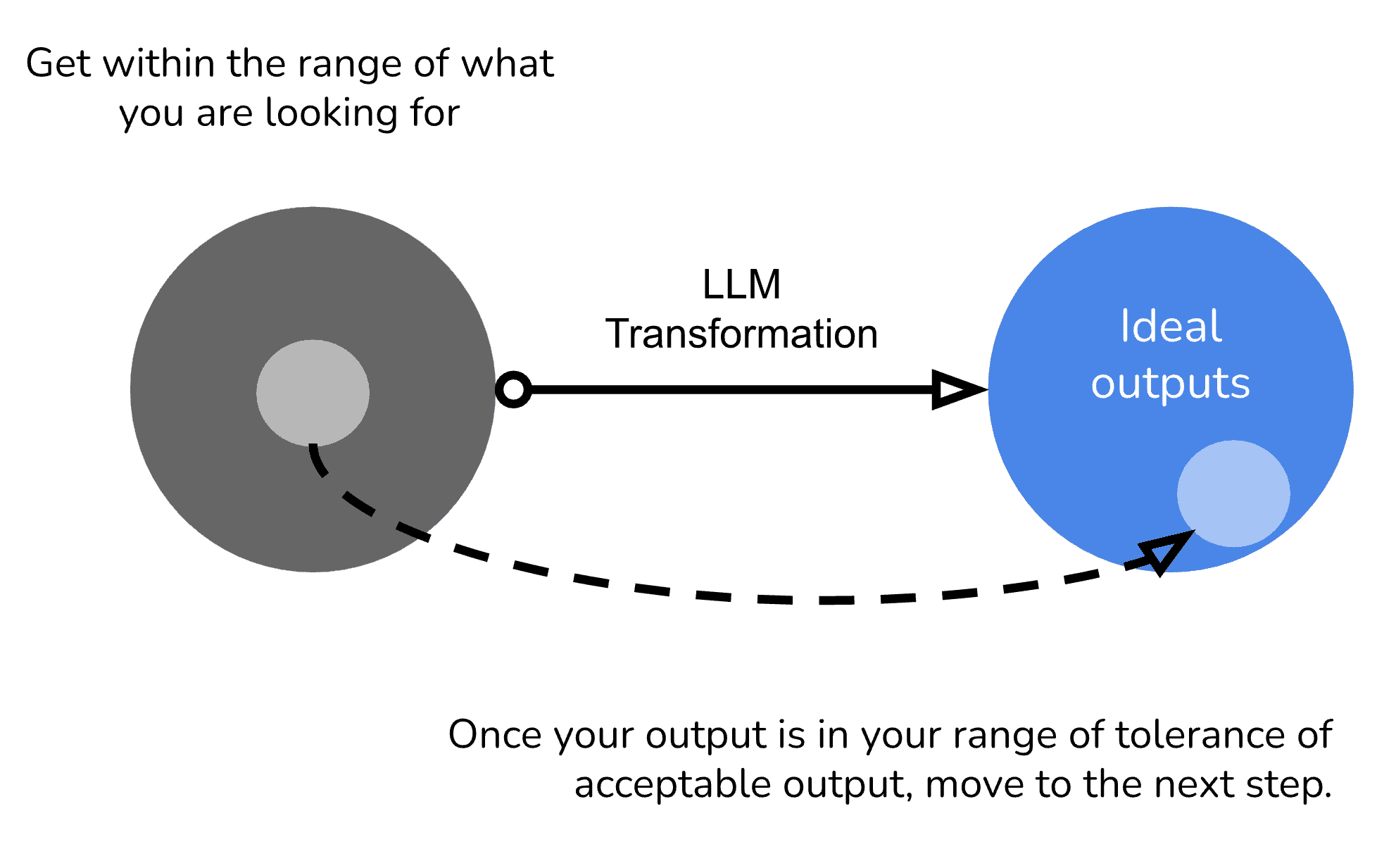
Note: If you are having trouble getting within the range, consider changing / reframing the output, play with a different LLM model. Or have a team member take a few attempts from a fresh perspective.
Slowly expand the variety of inputs
The next step is to try various inputs, and ensure the output is staying within the range of outputs you are expecting.
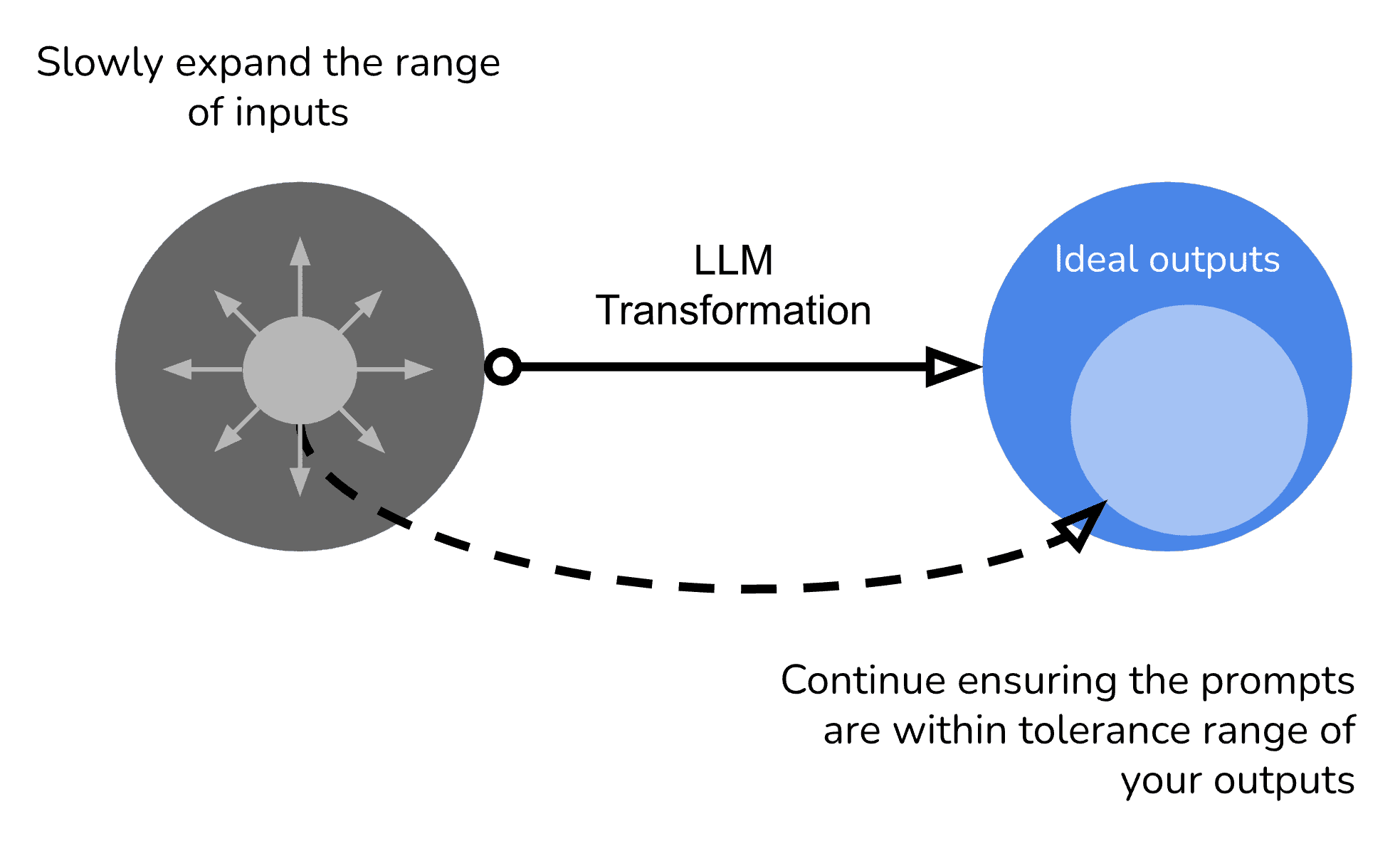
Find your failure points
Most likely you’ll get to the point where your inputs are spilling over into the bounds that are not acceptable. You’ve now started to hit the failure points of your prompt.
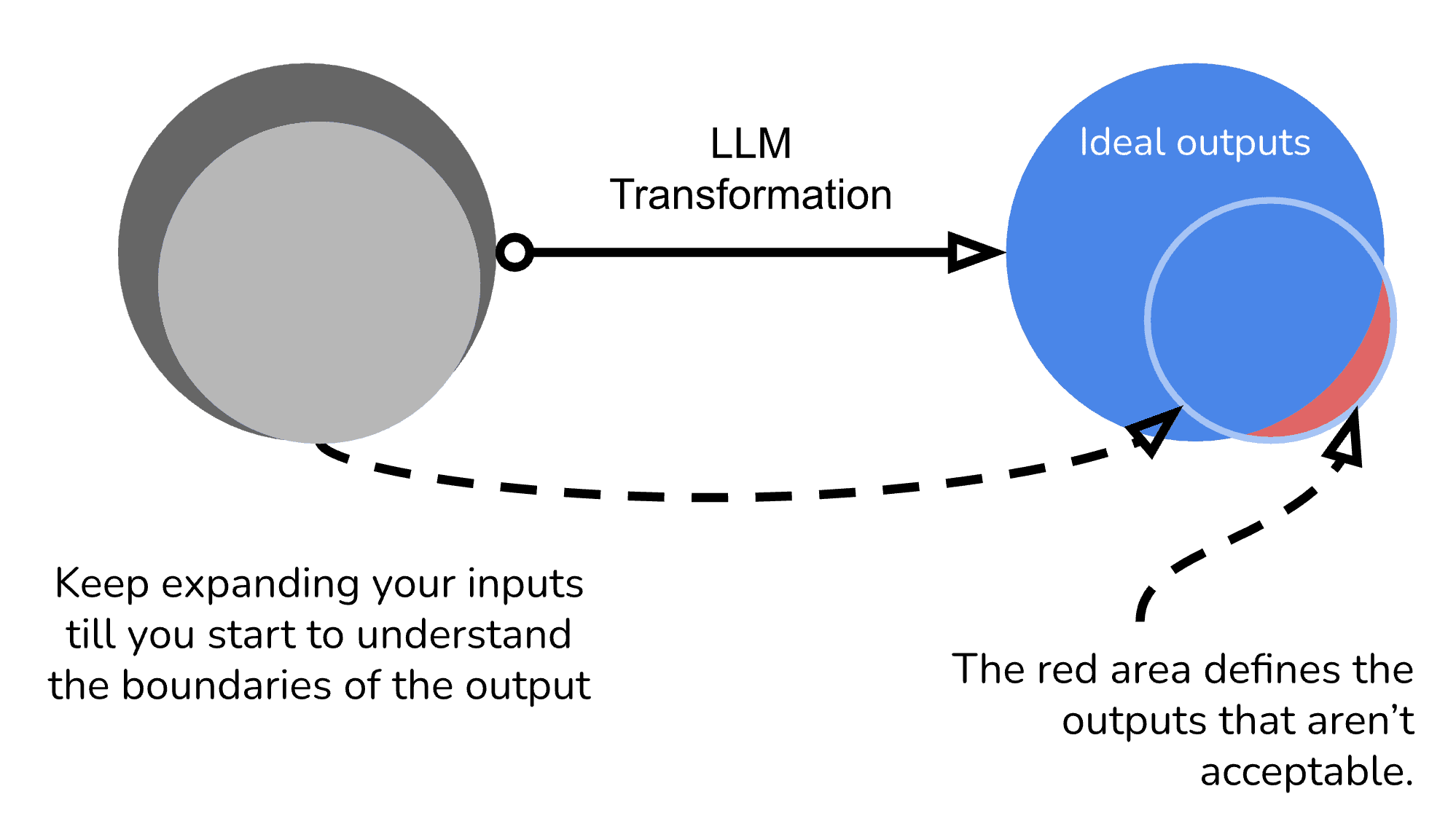
Fail Open or Fail Close
At this point it is important to determine whether you would like to "Fail Open or Fail Close". Fail open and fail close is a principle popular in cloud development that relates to error handling.
Fail open error handling - allows the software to continue operating despite encountering an error or exception. It essentially "fails open" by catching errors but letting execution continue, often returning a default value. This promotes availability and resilience, however, it risks returning bad data.
Fail closed error handling takes a safer approach. When an error is found, the software stops execution. It shuts down gracefully rather than attempt to continue with uncertain validity. However this may prevent useful operation of the software.
At NetworkGPT we have some clear rules and KPIs that we generally fail open where possible while ensuring a minimum 70 to 80% quality range. You’ll need to determine what is acceptable for your particular business and also the specific task you are assigned for your prompt. Industries like healthcare may not be able to afford mistakes, hence an approach to prevent such errors from reaching users is essential. You may need to train your teammates, project managers, and directors to understand how LLMs differ from traditional software.
Conclusion
Fundamentally language models are probabilistic, not deterministic. This is a large shift for traditional software engineering organizations to understand. Unlike classical coding, LLMs produce highly variable outputs for similar inputs. Steven Wolfram recently spoke about this topic. He described it in terms of his theory “computational irreducibility”. Essentially computational irreducibility refers to the inability to predict outcomes due to the complexity of the underlying computational process, leading to the perception of randomness. The statistical nature and inability to predict outcomes will mean that fail-closed applications will need to have specially architected guards to prevent a wrong answer from being returned. Your business model will dictate how much error-induced mistakes are acceptable.
“Science as what we have thought … where we feed in the input and we immediately make a prediction that's not going to work. That has many implications for AI. For example, if you say, I'm going to set up the rules for my AI and I'm going to get them just right, so I can know that my AI is never going to do the wrong thing.
Computational irreducibility says it's not going to work. You're just never going to know. … To know what it's going to do. You have to run it and see what it does.” - Steven Wolfram (Machine Learning Street Talk)
Success comes from the insights learned by exploring model behavior through iteration and pushing the prompts to their failure points. With software engineering, bugs surface from deviating from specifications; while with prompt engineering specifications are discovered through failure-driven learning.